
Loading cart contents...
Collision Detection Summary
Well, well…after a whole week of intense research, I think I already have some insight on Collision Detection so as to try to condense the matter in a post.
The following is a brief report made out of the references stated at the end:
INTRODUCTION
Collision detection is one of the major bottlenecks presented in any physics simulation given its computationally intensive idiosyncrasy.
It is also one of the main sources of error given that it serves as the basis for every other step in the simulation. Calculated collision points might later be treated as constraints within our solvers, or as force accumulators, and provide a lot of instabilities if they are not precise enough.
In general, collision detection / proximity queries / penetration depth algorithms are targeted to provide information about just that, to be used later for other things. These things are commonly physics simulations, haptic devices, or robotic simulations, and they require a real time speed of computation and robustness altogether.
A ROUGH REVIEW ON COLLISION DETECTION METHODOLOGIES FOR POLYGONAL MODELS
According to literature, it is possible to make an initial distinction depending on the nature of the graphic input data: polygonal models vs non-polygonal.


This separates the mostly common «soups of vertices» and triangles from solids, implicit surfaces and parametric surfaces.
Basically, all the researched collision detection methodologies focus on the first, as it is fairly easy to pre-process the others into polygon soups.
Furthermore, algorithms for non-polygonal surfaces are very specific and then would limit the input and the end user would be forced to provide information in this «format».
Once this distinction is made, each of the different algorithms focus on any or some of the following issues:
- Pair processing vs N-processing: If a method emphasizes too much on improving precision in the measurement of the distance between two particular meshes, then it becomes too slow and so it has a limit to the amount of bodies the simulation can represent.
- Static vs Dynamic: Others using the foreknown trajectories of the bodies require an amount of feedback between the dynamics engine and the collision detection package. Then the concept of frame coherence appears. These methods rely on the stable consistency of every time step to make calculations.
- Rigid vs Deformable: When the meshes represent cloths or fluids (deformable meshes), as the dynamic characteristics of their shape is often complex and essentially non-linear, robustness and efficiency are frequently affected.
- Large vs Small environment: There is also a problem generalizing the algorithms so they can serve as well in the short as in the long range, to avoid leaps in the numerical results that lead to instabilities and affect robustness.
BOUNDING VOLUME HIERARCHIES (BVHs)

An ubiquitous subject encountered in every researched method is that of the Bounding Volume Hierarchies.
These are a consequence of an iterative simplification of the problem of intersection of N bodies.
It consists in associating a simpler geometrical shape to our initial complex shape, so calculations of the distances can be made faster.
As long as couples of shapes gets closer and closer, we iteratively subdivide those rougher representations of them.
Many types have been devised:
Many types have been devised:
- k-DOP trees (Discrete Orientation Polytopes)
- Octrees
- R-trees
- Cone trees
- BSPs (Binary Space Partitions)

These trees are conformed of different simpler geometrical shapes that would be hierarchically sorted and that would represent our shapes within the tree.
There are various types:
There are various types:
- Spheres
- AABB (Axis Aligned Bounding Boxes)
- OBBs (Oriented Bounding Boxes)
- k-DOPs (Discrete Orientation Polytopes, where k means the number of faces)
- SSV (Swept Sphere Volumes)


The main procedure consists of getting statistical data from all the vertices for each mesh in order to get the centroid (the mean value of all of them) and the maximum and minimum values to have the bounding volume (of whatever the chosen shape). Then it is possible to use the specific characteristics of the shape to proceed to the interference calculations.
With spheres, it is quite straightforward, having their radius and centre. With bounding boxes it is possible to «project» the mesh vertexes coordinates against their sides. With these projections, a set of lists is made for each dimension (called intervals) and then check interference sorting the lists.
Actually these trees, or hierarchies, are just an abstraction to get different levels of definition during computation.
When made between objects far apart, we speak about broadphase. In this state the nested resulting bounding volumes are simpler and rougher and have little to do with the actual shape they contain.
When objects get closer then appears the narrowphase. It triggers whenever an intersection between two bounding volumes has been detected in the broadphase. Implies the iterative subdivision of the bounding volume, either until a collision point is found, or a penetration distance is calculated, or a separation distance is obtained.
In this part many different approaches can be found, with very prolix performance results and assumptions.
Nevertheless, particularly one sounds louder than others: the GJK algorithm.
Nevertheless, particularly one sounds louder than others: the GJK algorithm.
GJK ALGORITHM AND THE MINKOWSKY SUM
A principal character in this play is the GJK (Gilbert-Johnson-Keerthy) algorithm.
It implements an algebraic property of every pair of convex polyhedra: the Minkowsky sum.
Basically this sum (or difference, there is not much consensus but I am not a mathematician either), has the ability of returning a very important concept: when two convex polyhedra are added through it, if they share a part of the space (they intersect), the centroid of them is contained within the resulting polyhedron.
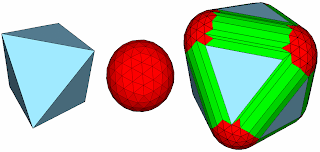

For every pair of objects that need to have their interference checked (remember, it triggers only between those objects that are close), all that has to be done is to iteratively see whether the features (vertices, edges and faces) are getting close or far from the centroid.
This is made using the concept of simplex, that can be applied to vertices, edges, triangles or tetrahedra (all of them known as polytopes).
Making a single loop that iterates through the mesh geometry, it is possible to discard the interference whenever a vector points out from the direction of the centroid of the Minkowsky sum. If none appears, then objects are overlapping.
This is made using the concept of simplex, that can be applied to vertices, edges, triangles or tetrahedra (all of them known as polytopes).
Making a single loop that iterates through the mesh geometry, it is possible to discard the interference whenever a vector points out from the direction of the centroid of the Minkowsky sum. If none appears, then objects are overlapping.
This algorithm has an irrefutable efficiency, provided its popularity, and has proven to pass from an O(n2) complexity to O(nlogn) complexity.
Mainly it comes from the fact that gives a true / false answer very quickly, as it does not need to iterate the whole geometry for the answer (usually comes after a few iterations over the simplex checking algorithm).
Mainly it comes from the fact that gives a true / false answer very quickly, as it does not need to iterate the whole geometry for the answer (usually comes after a few iterations over the simplex checking algorithm).
The first problem one encounters is that distances are not straightforward in this method. The way to obtain penetration distance requires further processing and affects performance negatively when implemented. An error tolerance has to be provided and then successive iterations are made in a very similar manner to the «sweep and prune» way described above: testing that a «shrinking» polytope from the centroid is as small as this error.
Another drawback of this method is its limitation to convex polyhedra. Minkowsky sum property does not apply for concave polyhedra.
This can be tackled using a preprocessing convex shape decomposition that would provide us with sets of Bounding Volume Hierarchies nested within the initial concave shape.
Last but not least is the instability problem that arises when very small shapes are tested against larger ones. Due to the difference in size, the Minkowsky sum presents extremely oblong shaped facets. This commonly leads to infinite loops.
OPEN SOURCE COLLISION DETECTION
The following is a list describing all available Open Source algorithms I have tested and helped me out to figure out the described above:
- I-COLLIDE collision detection system: is an interactive and exact collision-detection library for environments composed of many convex polyhedra or union of convex pieces, based on the expected constant time, incremental distance computation algorithm and algorithms to check for collision between multiple moving objects.
- RAPID interference detection system: is a robust and accurate polygon interference detection library for pairs of unstructured polygonal models. It is applicable to polygon soups models which contain no adjacency information and obey no topological constraints. It is most suitable for close proximity configurations between highly tesselated smooth surfaces.
- V-COLLIDE collision detection system: is a collision detection library for large dynamic environments, and unites the nbody processing algorithm of I-COLLIDE and the pair processing algorithm of RAPID. It is designed to operate on large numbers of static or moving polygonal objects to allow dynamic addition or deletion of objects between timesteps.
- SOLID interference detection system: is a library for interference detection of multiple three-dimensional polygonal objects including polygon soups undergoing rigid motion. Its performance and applicability is comparable to that of V-COLLIDE.
- SWIFT++: SWIFT++ is a collision detection package capable of detecting intersection, performing tolerance verification, computing approximate and exact distance, or determining the contacts between pairs of objects in a scene composed of general rigid polyhedral models. It is a major extension of the SWIFT system previously released from UNC. Uses the convex polyhedra decompostion.
- OPCODE: It is similar to popular packages such as SOLID or RAPID, but more memory-friendly, and often faster. Stands for OPtimized COllision Detection.
-
PQP proximity query package: It pre-computes a hierarchical representation
of models using tightting oriented bounding box trees (OBBTrees). At runtime, the algorithm traverses two such trees and tests for overlaps between oriented bounding boxes based on a separating axis theorem, which takes less than 200 operations in practice.
Conoce el programa, la nueva metodología de diseño: "Co-Creación Procedural"
Clic aqui si quieres entender como generar sinergías entre algoritmos, diseñadores y empresas para crear nuevos productos y servicios que generan ingresos pasivos. ¿Te quedarás atrás?, otros ya están usando el poder de los algoritmos y co-creando con ellos. ⇱